Microsoft опубликовал результаты исследования SkillOpt, которое демонстрирует, как Codex может перестать быть просто хранилищем статей и стать активным участником процесса разработки агентных систем. В отличие от традиционного подхода, когда идеи из научных работ остаются на уровне теории, SkillOpt предлагает практический воркфлоу: статья → цель → локальная реализация. Этот метод уже используется для оптимизации GPT-5.5 внутри среды Codex, где скиллы агента рассматриваются как обучаемое внешнее состояние.
Основной механизм SkillOpt заключается в том, что после запуска rollout (тестового развертывания) скилл агента редактируется и валидируется. Важно, что изменения сохраняются только в том случае, если они действительно улучшают результат. Это позволяет избежать накопления ненужных модификаций и фокусироваться на приросте эффективности. В ходе экспериментов SkillOpt показал прирост производительности GPT-5.5 на 24,8 пункта по сравнению с baseline — версией агента без использования скиллов.
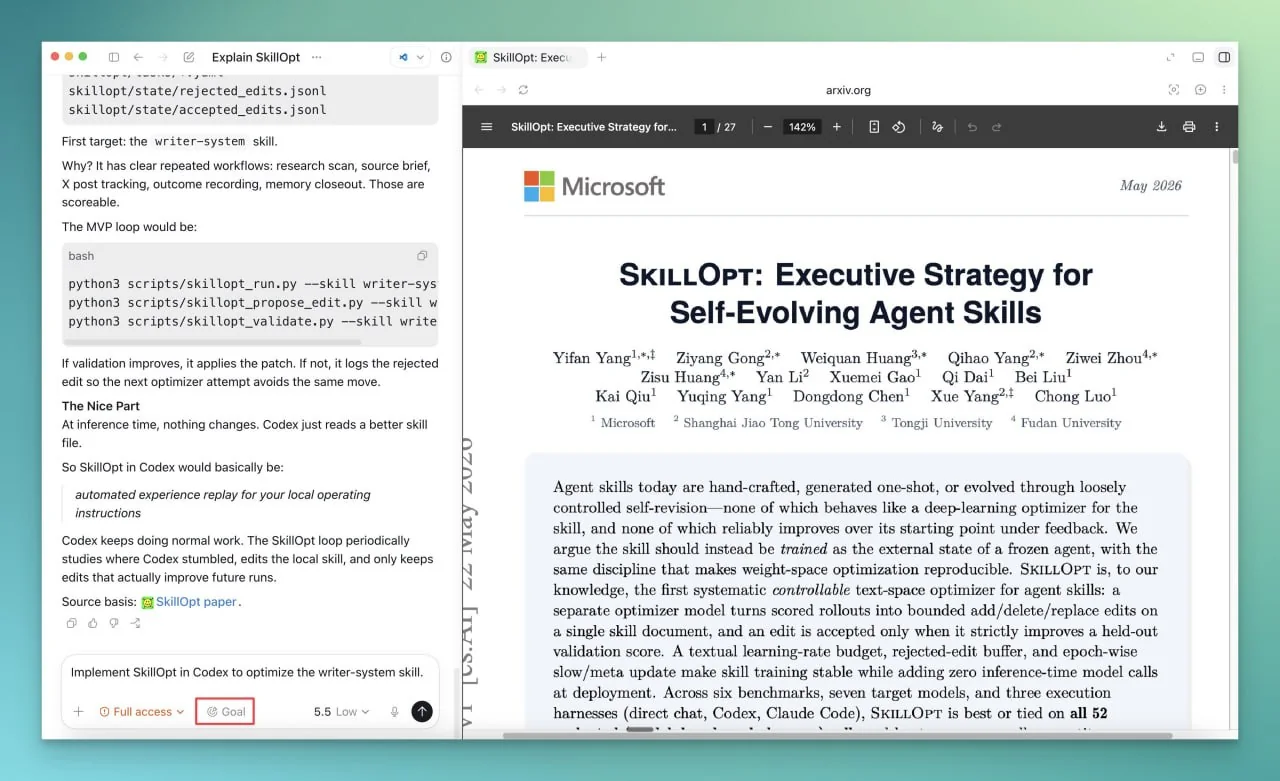
Эксперты отмечают, что этот подход особенно актуален для разработчиков, работающих с Codex. Достаточно взять любую новую статью по агентным системам, задать себе вопрос: «Как это применить в моей локальной конфигурации?» — и перейти в режим /goal. Такой воркфлоу позволяет не просто сохранять статьи в закладки, но и сразу тестировать идеи в рабочей среде. Например, если в исследовании описывается новый метод работы с памятью агентов, его можно сразу адаптировать под Codex и проверить на практике.
Особое внимание в SkillOpt уделяется harness engineering — набору техник, которые помогают структурировать и оптимизировать работу агентов. Это включает в себя не только настройку скиллов, но и работу с обратной связью, инструментами, и даже scaffolds — вспомогательными конструкциями, которые облегчают выполнение сложных задач. Важно, что все эти элементы могут быть интегрированы в Codex без необходимости глубоких изменений в архитектуре.
Для разработчиков, которые только начинают экспериментировать с агентными системами, SkillOpt открывает новые возможности. Например, можно взять статью о том, как улучшить eval loops (циклы оценки) в агентах, и сразу применить эти идеи в своей локальной среде. Это позволяет не только изучать теории, но и видеть их практическое применение в реальном времени. Более того, такой подход ускоряет процесс обучения и адаптации новых методов, так как результаты становятся очевидны сразу после внедрения.
Однако стоит учитывать, что эффективность SkillOpt зависит от качества исходных данных и правильной настройки параметров. Например, если скиллы агента некорректно валидируются, это может привести к накоплению ошибок и снижению общей производительности. Поэтому важно тщательно тестировать каждое изменение и отслеживать метрики успеха. В случае с GPT-5.5 прирост на 24,8 пункта был достигнут именно благодаря строгому контролю над изменениями и их валидации.