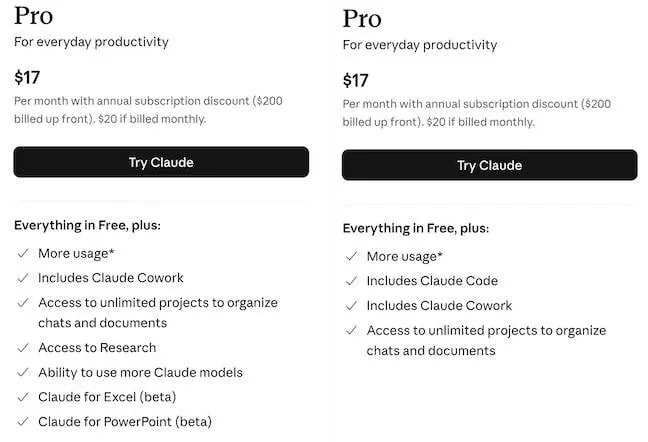
Платформа X, ранее известная как Twitter, выложила на GitHub часть кода, отвечающего за работу алгоритма рекомендаций For You. В репозитории xai-org/x-algorithm теперь доступен код системы, которая отвечает за подбор и ранжирование контента в пользовательской ленте. Это первый случай, когда X открывает исходники такого масштаба для публичного доступа.
В основе алгоритма лежат два ключевых источника контента: посты от аккаунтов, на которые подписан пользователь, и публикации из глобального корпуса, отобранные с помощью машинного обучения. Далее весь массив данных проходит через модель Phoenix — трансформер на базе архитектуры Grok. Эта модель анализирует вероятность взаимодействия пользователя с контентом: лайки, реплаи, репосты, клики и другие сигналы. На основе этих оценок система формирует итоговый рейтинг, определяя, какие посты попадут в ленту.
Открытие кода позволяет разработчикам и исследователям изучить не только логику ранжирования, но и понять, какие именно сигналы влияют на рекомендации. В репозитории также можно ознакомиться с тем, как устроен весь пайплайн обработки данных — от первичного отбора кандидатов до финальной сортировки. Это даёт возможность оценить, как платформа фильтрует и приоритизирует контент перед показом пользователю.
Эксперты отмечают, что публикация кода может стать важным шагом для повышения прозрачности работы алгоритмов социальных сетей. Теперь любой желающий сможет проверить, насколько объективно система формирует ленту, и выявить возможные смещения или предвзятость в рекомендациях. Это особенно актуально на фоне постоянных обсуждений влияния алгоритмов на информационную повестку.
Для разработчиков и аналитиков доступ к коду открывает новые возможности для исследований в области обработки естественного языка и рекомендательных систем. В будущем такие инициативы могут способствовать появлению более точных и справедливых алгоритмов, которые лучше учитывают интересы пользователей.