Китайский исследователь из университета Цинхуа представил новый подход к оценке количества параметров в языковых моделях, который основан на анализе объёма фактических знаний, а не на экономике инференса. Этот метод позволяет получить более точные оценки для закрытых систем, таких как GPT-5.5, Claude Opus 4.6 или Gemini 2.5 Pro, которые традиционно скрывают свои архитектурные детали.
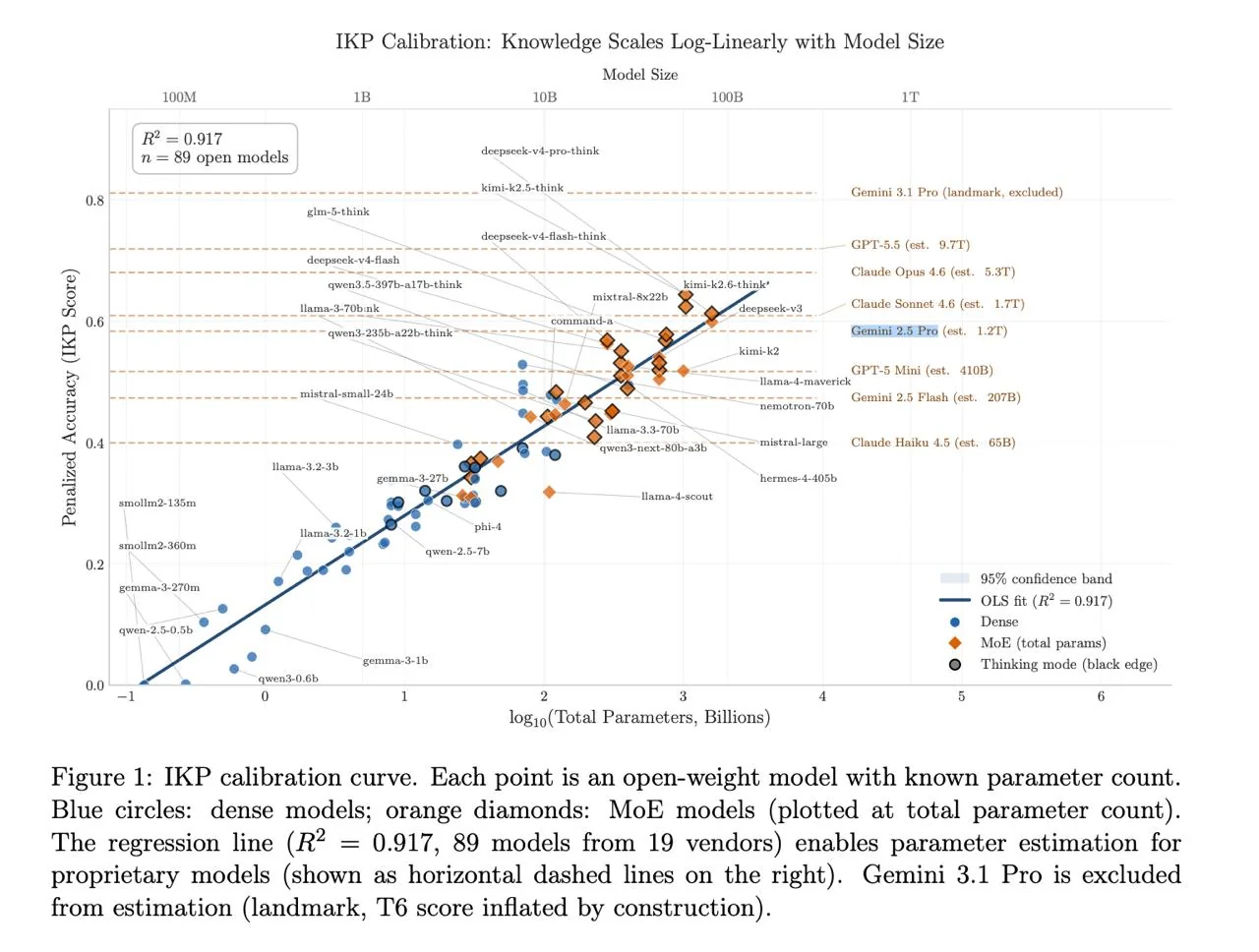
Автор работы, опубликованной 27 апреля 2026 года на платформе arXiv, создал бенчмарк из 1400 вопросов, охватывающих факты разной степени редкости — от широко известных до крайне специализированных. Эти вопросы были использованы для тестирования 89 открытых моделей с известным числом параметров. Результаты показали чёткую лог-линейную зависимость между количеством параметров и точностью ответов на вопросы: коэффициент детерминации R² составил 0,917. Это означает, что модель с большим количеством параметров способна хранить и извлекать больше фактической информации.
Исследователь применил разработанную методику к оценке параметров закрытых моделей, сравнив их результаты с калибровочной кривой. Полученные оценки оказались неожиданными: GPT-5.5, по расчётам, может содержать около 9,7 триллиона параметров, что значительно превышает аналогичные показатели конкурентов. Claude Opus 4.6 оценивается в 5,3 триллиона параметров, а Claude Sonnet 4.6 — в 1,7 триллиона. Gemini 2.5 Pro, согласно расчётам, насчитывает около 1,2 триллиона параметров. Важно отметить, что эти оценки являются нижними границами, так как некоторые модели могут отказываться отвечать на определённые вопросы из-за настроек безопасности.
Несмотря на то, что метод не лишён погрешностей, он открывает новые возможности для анализа закрытых моделей, которые ранее оставались недоступными для независимых исследователей. Это может способствовать более прозрачному сравнению архитектур и стимулировать развитие открытых альтернатив. В то же время, точность оценок зависит от качества бенчмарка и калибровки, что требует дальнейших исследований и уточнений.
Работа китайского учёного подчёркивает важность фактических знаний как ключевого ресурса в развитии больших языковых моделей. В отличие от способностей к рассуждению, которые можно дистиллировать в более компактные архитектуры, объём фактических данных ограничен энтропией Шеннона и напрямую зависит от размера модели. Это делает предложенный метод особенно ценным для оценки закрытых систем, где традиционные подходы дают значительную погрешность.