Китайская лаборатория Hunyuan представила в открытом доступе новую модель Hy3, которая стала первым релизом после полной перестройки инфраструктуры предобучения и обучения с подкреплением. Новинка сочетает 295 млрд параметров, из которых 21 млрд активны, и поддерживает контекстное окно в 256 тыс. токенов — это один из самых больших показателей среди современных языковых моделей.
Hy3 реализована как гибридная MoE-архитектура с двумя режимами работы: быстрым и медленным мышлением. Это позволяет модели адаптироваться под разные типы задач — от генерации текста до сложных аналитических вычислений. По данным разработчиков, время до первого токена сократилось на 54%, а полное время ответа — на 47%, что делает модель более отзывчивой даже при работе с объемными документами.
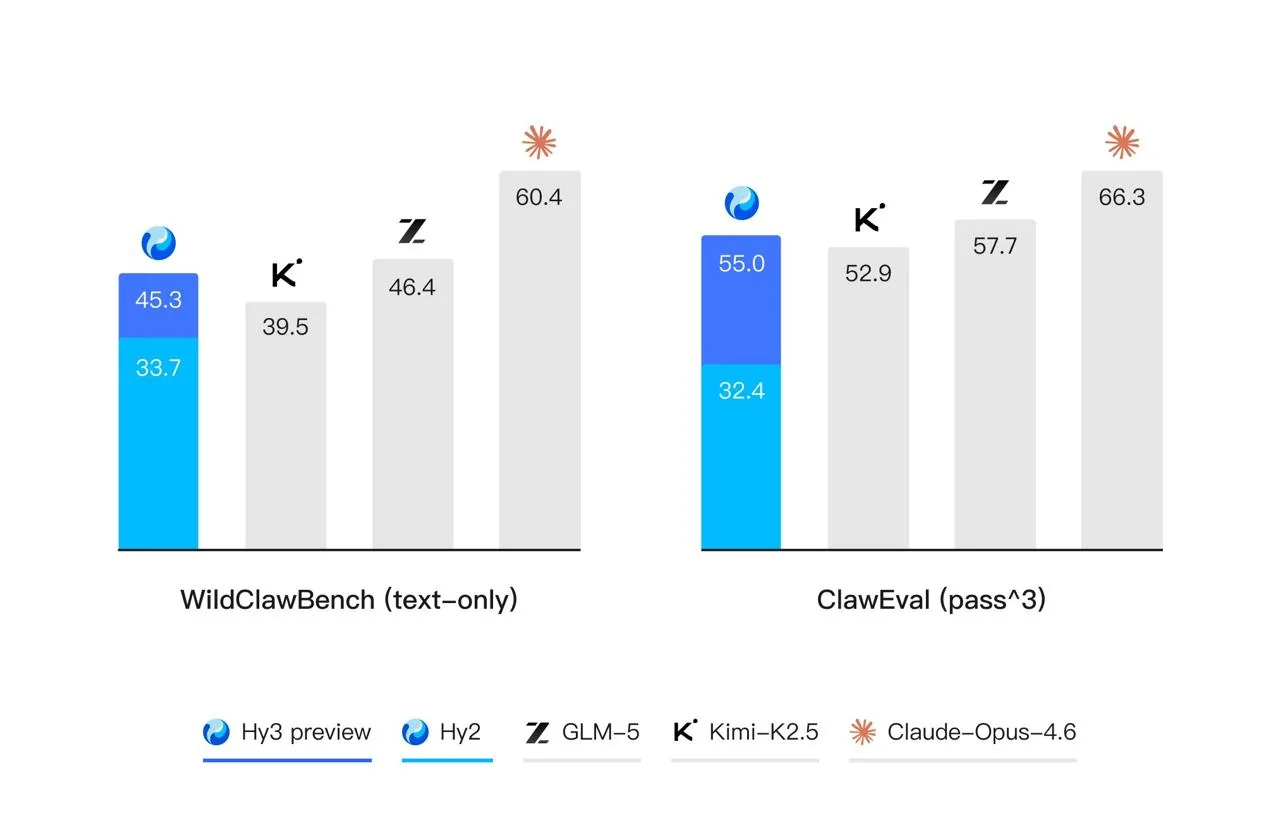
В продакшене модель демонстрирует высокую стабильность: на живых задачах CodeBuddy и WorkBuddy Hy3 ошибается менее чем в 0,01% случаев. На стандартных бенчмарках, таких как SWE-bench Verified для программирования, Terminal-Bench 2.0 для работы с терминалом, а также BrowseComp и WideSearch для веб-поиска, модель показывает результаты, сопоставимые с топовыми кодинговыми и поисковыми агентами.
Hy3 совместима с популярными фреймворками, включая OpenClaw, OpenCode и KiloCode, а для запуска доступны оптимизированные решения vLLM и SGLang. Разработчики подчеркивают, что модель способна обрабатывать цепочки из 495 шагов в производственных сценариях, что открывает возможности для создания сложных агентов, работающих с документами, аналитикой данных и MCP-инструментами.
Новый релиз Hunyuan Hy3 стал важным шагом в развитии открытых моделей с большим контекстом и высокой производительностью. Его появление может ускорить внедрение продвинутых ИИ-решений в корпоративной аналитике, программировании и автоматизации бизнес-процессов.